According to Claris’ FileMaker Pro Release Notes for Version 20.3.1,
Flush includes the following three values:
1. Always: When setting a field within a loop, the relationship is flushed along with the join data.
2. Minimum: When setting a field within a loop, minimal data is flushed.
3. Defer: When setting a field within a loop, data and relationship data are flushed only after exiting the loop.
What does that mean, and how does it impact your FileMaker solutions?
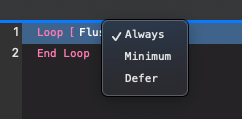
The new flush option for the loop script step
Understanding Relationships and Join Data
We can use relationships to fetch and display data from related tables.
In this scenario, consider the relationship as a tunnel going from the current record in the current table to the related table, helping us locate related records.
Whenever a relationship is established, FileMaker will use the relationship to identify related records, query related data, and cache the queried result. These cached related records’ data are referred to as join data.
If we update the value of one of the fields used on the left side of the relationship, typically, FileMaker will need to re-establish the relationship (find related records again) and re-query the join data (fetch related records’ data via the relationship again).
For example, I have a relationship shown in the screenshot below. It is used to display a list of related records in a portal. On the left side of the relationship, I use a global field zgtProjectCategoryFilter, to show only related records with a matching project category.
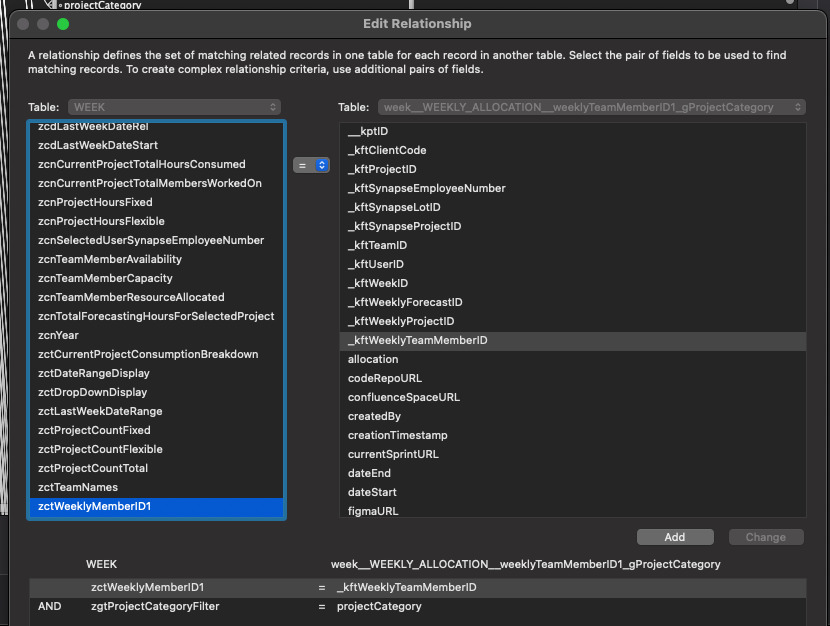
A relationship used for a filterable portal
On the layout, the user can set the value of zgtProjectCategoryFilter to one of the three values using these buttons:
Whenever a user changes the value, FileMaker will need to flush the cached join data, re-establish the relationship and re-query the join data so the portal displayed on the layout can achieve the “filtering” effect.
Performance Implication
Now that we understand relationships and join data, what are the implications of the new flush option?
Imagine you have a script that loops. Each time it loops, it updates a field on the left side of a relationship. Imagine this field is used in multiple relationships, and a large amount of join data might be fetched through those relationships. By default, FileMaker will flush and re-query every time the left side field is updated. This could have a serious performance implication for your solution, especially if it runs over the WAN (check out this video to understand why).
Before version 20.3.1, we had some, but limited, control over when FileMaker flushed the join data (with the Refresh Window script step), but not when it comes to looping that sets fields used in relationships. Under the loop scenario, FileMaker will always flush and re-query, regardless of necessity.
With Version 20.3.1, this new feature gives developers control over when FileMaker should re-establish the relationship and flush join data. It allows us to avoid expensive flush operations when unnecessary.
Let’s take a second look at the release notes—this time, you should have a bit more context:
Flush includes the following three values:
1. Always: When setting a field within a loop, the relationship is flushed along with the join data.
2. Minimum: When setting a field within a loop, minimal data is flushed.
3. Defer: When setting a field within a loop, data and relationship data are flushed only after exiting the loop.
Always is what we had before this version, and it is the default option. If you open up a FileMaker solution using FileMaker Pro version 20.3.1+ for the first time, all of your loop flush options will be set to Always. This flushes not when it’s necessary, but when it can.
Defer is fast. Its behavior is simple: it will try not to flush anything until exiting the loop. There will be one flush, in total, at the end.
Minimum is a bit mysterious. At the time of this article’s publication, there’s no official documentation on this feature other than what’s quoted above. The name seems to indicate that this option is doing something smart to minimize the amount of join data flushed while looping. Based on my testing, my guess is that its behavior is between Always and Defer; Minimum tries to do as few flushes as possible, unless other script steps in the loop require a flush.
Behavior and Performance Tests
Testing Method
To test this feature, I used a scenario like what I described above: one field that is part of nine different relationships gets updated repeatedly.
In the earlier example, I only showed one relationship with the global field. In reality, I have nine of them.

Nine relationships that use the zgtProjectCategoryFIlter field on the left side
This is probably not the smartest way for me to build a grid view in FileMaker, but it’s perfect for testing out this new feature.
The testing script I used is shown in the screenshot below. It runs from a layout that uses these relationships to display related data in portals. The script loops many times, and each time it loops, it sets the zgtProjectCategoryFilter field to a different value; in the end, it spits out the total time taken, and a list of related data fetched.
Testing Process and Data
Test Case 1 – 999 loops, fetch join data mid-loop & evaluate portals
For the first test, inside each loop, I tried to fetch one piece of join data and record it.
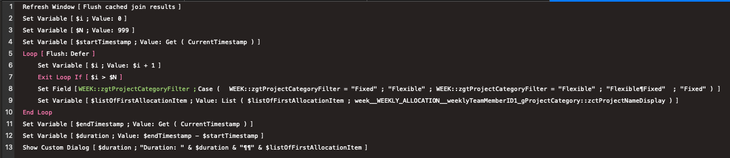
Script used
| Testing Scenario | Always | Minimum | Defer | |
| 1 | 999 loops 9 relationships 23 related records at most 2023-11-26 | 22 seconds Mid-loop data fetched is accurate | 18 seconds Mid-loop data fetched is accurate | 1 seconds Mid-loop data fetched is NOT accurate |
| 2 | 999 loops 9 relationships 13 related records at most 2023-12-10 | 21 seconds Mid-loop data fetched is accurate | 18 seconds Mid-loop data fetched is accurate | ~0 seconds Mid-loop data fetched is NOT accurate |
| 3 | 999 loops 5 relationships 13 related records 2023-12-24 | 21 seconds Mid-loop data fetched is accurate | 18 seconds Mid-loop data fetched is accurate | ~0 seconds Mid-loop data fetched is NOT accurate |
Test Case 2 – 999 loops, only evaluate portals
Now, let me disable the step that fetches the related data in the middle of the loop, leaving only the layout utilizing join data.
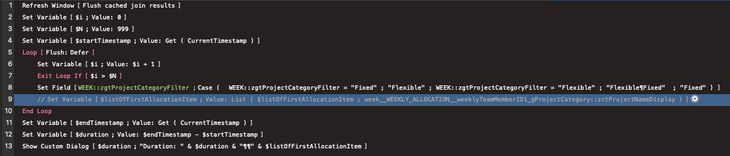
Script used
| Testing Scenario | Always | Minimum | Defer | |
| 1 | 999 loops 9 relationships 23 related records at most | 1 seconds | ~0 seconds | ~0 seconds |
| 2 | 999 loops 9 relationships 13 related records at most | ~0 seconds | ~0 seconds | ~0 seconds |
| 3 | 999 loops 5 relationships 13 related records | ~0 seconds | ~0 seconds | ~0 seconds |
Test Case 3 – 99,900 loops, only evaluate portals
To test the overhead introduced by layouts during loops, I cranked up the total loop count by a hundredfold to 99,900.
| Testing Scenario | Always | Minimum | Defer | |
| 1 | 99,900 loops 9 relationships 23 related records at most | 50 seconds | 10 seconds | 8 seconds |
| 2 | 99,900 loops 9 relationships 13 related records at most | 49 seconds | 9 seconds | 9 seconds |
| 3 | 99900 loops 5 relationships 13 related records | 47 seconds | 9 seconds | 9 seconds |
Bonus Test Case – 99,900 loops, only evaluate portals & data viewer accidentally left open with “automatically evaluate” on
Accidentally leaving the data viewer open significantly slowed down the process. Even though I’m not using it to watch any join data relevant to my test.
Conclusions & Usage Considerations
- The Defer option does not flush join data in the middle of the loop at all. This is why, in test case 1, the mid-loop join data fetched with the Defer option is inaccurate.
- This verifies the behavior mentioned in the release notes.
- This also explains why it’s the fastest among the three options.
- We should only use the Defer option when the join data is irrelevant to the loop logic. Otherwise, we will get the wrong data.
- The Always option is the slowest, as we expected.
- The Minimum option’s performance is between Always and Defer.
- It tries to keep the mid-loop join data evaluation accurate, as shown in test case 1.
- However, the more “avoidable join data flush” there is, the more performant it becomes, to the point that it could be comparable to the Defer option’s performance (compare results from test cases 1 and 3).
- This seems to be the no-brainer option here, but please don’t quote me on this. Let’s wait for the official documentation that clarifies the behavior before mass adoption.
- Different operations that rely on relationships have different performance overheads.
- Explicitly fetching join data in the script introduces a much bigger performance overhead than related fields displayed on layouts (compare results from test cases 1 and 2).
- The number of relationships touching the field being updated doesn’t matter much. The number of related records does matter a little bit. This makes sense as the number of related records determines the number of join data that could be fetched (test case 3).
- Data viewer changes FileMaker’s evaluation/flush behaviour (bonus test case).
One More Thing
Inspired by this thread, we could use this new flush option with the single-pass-loop technique to control the join data flushing behavior of the entire script.
I hope this article sheds some light on this new feature.