L’outil de migration des données FileMaker (FM DMT / “FileMaker Data Migration Tool”) est un outil formidable qui aide les développeurs à effectuer des déploiements. Pour apprendre à utiliser FM DMT, consultez notre vidéo ici : FileMaker Best Practices: The Data Migration Tool.
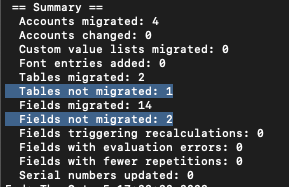
Après avoir utilisé FM DMT pour migrer des données d’un fichier à un autre, il est bon de vérifier le résumé à la fin pour repérer les problèmes potentiels.
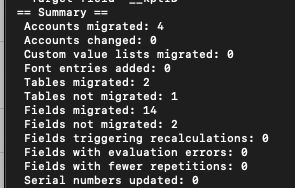
Parfois, nous trouverons un certain nombre de tables ou de rubriques non migrées. Pas de panique ! Cet article traite de l’identification des tables et des rubriques qui ne sont pas migrées et de ce qu’il faut faire par la suite.
Exécutez le DMT en mode verbal
Si l’exécution précédente n’était pas en mode verbal – “verbose mode” en anglais, (avec l’option -v dans la ligne de commande), exécutez à nouveau le DMT, mais cette fois-ci, activez le mode verbal. Vous obtiendrez ainsi un journal de migration beaucoup plus détaillé, qui vous indiquera ce qui a fonctionné et ce qui n’a pas fonctionné.
Consultez l’exemple de commande ci-dessous. Notez le « -v » à la fin, qui indique que la commande sera exécutée en mode verbal cette fois-ci.
FMDataMigration -src_path "SourceFile.fmp12" -src_account "source account" -src_pwd "source password" -clone_path "CloneFile.fmp12" -clone_account "clone account" -clone_pwd "clone password" -vAprès avoir exécuté le DMT en mode verbal, je vous conseille de copier le journal détaillé hors de l’outil de ligne de commande et dans un éditeur de texte pour faciliter la recherche.
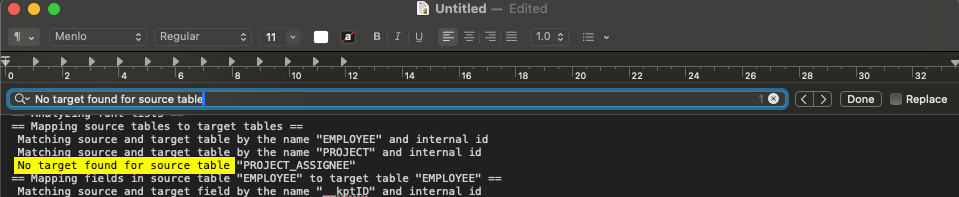
Identifier les tables non migrées
Le moyen le plus simple de trouver les tables non migrées est de rechercher la phrase « No target found for source table ». Cela devrait vous aider à localiser les tables présentes dans le fichier source qui ne sont pas dans le fichier cible.
Notez que parfois, après avoir effectué une récupération sur un fichier, FileMaker génère automatiquement des tables nommées » Récupération XXX » Si vous avez effectué une récupération sur votre fichier cible, il se peut que ces tables de récupération ne migrent pas, ce qui n’est pas très grave.
Les modifications du schéma de données peuvent empêcher la migration des tables, comme la suppression de tables dans votre fichier cible mais pas dans votre fichier source, ou la création de tables dans la source mais pas dans la cible.
Identifier les rubriques non migrées
Le moyen le plus simple de trouver les rubriques non migrées est de rechercher la phrase « No compatible target » (pas de cible compatible). Cela vous aidera à trouver les rubriques qui se trouvent dans la source mais pas dans la cible.
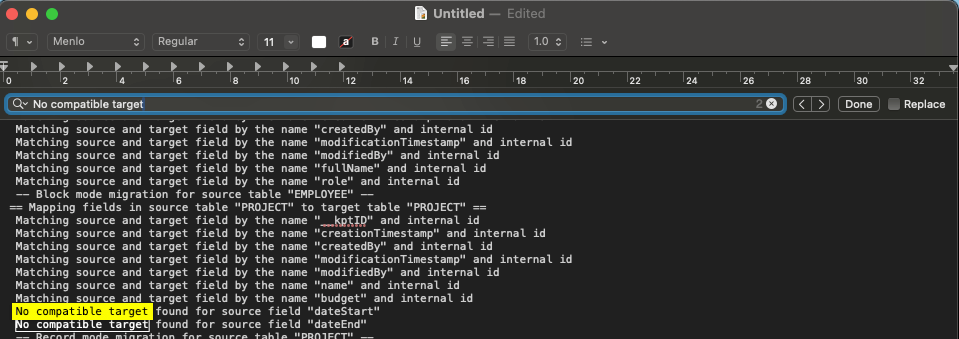
Pour savoir à quelle table cette rubrique appartient, faites défiler l’écran jusqu’à ce que vous trouviez le texte » == Mapping fields in source table XXXX » le plus proche.
Les modifications du schéma de données, telles que la suppression de rubriques dans votre fichier cible ou la création de rubriques dans votre source, sont les raisons les plus courantes pour lesquelles les rubriques ne sont pas migrées.
Que faire après avoir identifié les tables/rubriques non migrées ?
Nous voulons identifier ces tables et ces rubriques pour déterminer s’ils ont nui à notre migration/déploiement. Pour faire court, ils ne sont pas tous mauvais. Ce que nous recherchons, ce sont des éléments auxquels nous ne nous attendions pas.
Certaines modifications empêcheront naturellement les tables et les rubriques de migrer. Par exemple, si vous supprimez intentionnellement une table ou une rubrique dans le fichier cible, il est tout à fait normal que cette table/rubrique ne migre pas depuis la source. Toutefois, la suppression d’une table ou d’une rubrique constitue un changement assez important. Veillez à utiliser votre DDR pour effectuer des analyses de référence et vous assurer que la suppression de ce contenu ne posera pas de problème à votre application.
D’un autre côté, vous pourriez trouver des choses auxquelles vous ne vous attendiez pas. Il se peut que vous trouviez une table ajoutée au fichier source par un développeur et qu’en raison d’une mauvaise communication, vous n’en ayez jamais eu connaissance. Ces surprises doivent inciter les développeurs à clarifier la situation et à envisager éventuellement d’interrompre le déploiement, de revenir en arrière et de reprogrammer le déploiement.
Une leçon importante que j’ai apprise (à la dure) est que dans la plupart des situations, il vaut mieux demander un retour en arrière et reprogrammer le déploiement plutôt que d’essayer de « tenir le coup » et de procéder à un dépannage massif le jour du déploiement.
Que puis-je faire pour éviter les surprises ?
En règle générale, si des activités liées au déploiement peuvent être réalisées avant le déploiement proprement dit, nous les réalisons avant le déploiement. Nous voulons planifier, tester et répéter avant le jour du déploiement afin d’éliminer autant d’incertitudes que possible.
Supposons que je sois confronté à un déploiement très important (par exemple, certaines organisations exigent que leur application FM ait un temps de disponibilité très élevé. Le temps d’arrêt nécessaire au déploiement pourrait donc leur coûter très cher). Dans ce cas, j’effectuerai un essai à sec “dry-run” en suivant les procédures de déploiement sans télécharger le fichier migré dans l’environnement de production. Au cours de cette simulation, j’utiliserai le DMT pour la migration des données. Ainsi, s’il y avait des surprises potentielles, je les trouverai avant le déploiement réel et j’aurai tout le temps de m’en occuper.
J’espère que cet article vous aidera à résoudre les problèmes ou, mieux encore, à préparer à des déploiements sans heurts.