Selon les notes de mise à jour de FileMaker Pro de Claris pour la version 20.3.1,
L’option Purge comprend les trois valeurs suivantes :
1. Systématique : lors de la définition d’une rubrique dans une boucle, le lien est purgé avec les données de jointure.
2. Minimale : lors de la définition d’une rubrique dans une boucle, les données minimales sont purgées.
3. Différée : lors de la définition d’une rubrique dans une boucle, les données et les données de lien ne sont purgées qu’après avoir quitté la boucle.
Qu’est-ce que cela signifie et quel est l’impact sur vos solutions FileMaker ?
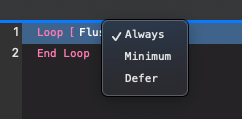
La nouvelle option de purge pour l’action de script Boucle
Comprendre les liens et les données de jointure
Nous pouvons utiliser les liens pour récupérer et afficher des données provenant de tables liées.
Dans ce scénario, considérez le lien comme un tunnel allant de l’enregistrement actuel de la table courante à la table liée, ce qui nous aide à localiser les enregistrements liés.
Chaque fois qu’un lien est établi, FileMaker l’utilise pour identifier les enregistrements liés, interroger les données liées et mettre en cache le résultat de la requête. Ces données d’enregistrements liés mises en cache sont appelées données de jointure.
Si nous mettons à jour la valeur de l’une des rubriques utilisées du côté gauche du lien, FileMaker devra rétablir le lien (trouver à nouveau des enregistrements liés) et interroger à nouveau les données de jointure (récupérer à nouveau les données des enregistrements liés via le lien).
Par exemple, j’ai un lien illustré dans la capture d’écran ci-dessous. Elle est utilisée pour afficher une liste d’enregistrements liés dans une table externe. Sur le côté gauche de la relation, j’utilise un champ global, zgtProjectCategoryFilter, pour n’afficher que les enregistrements liés dont la catégorie de projet correspond.
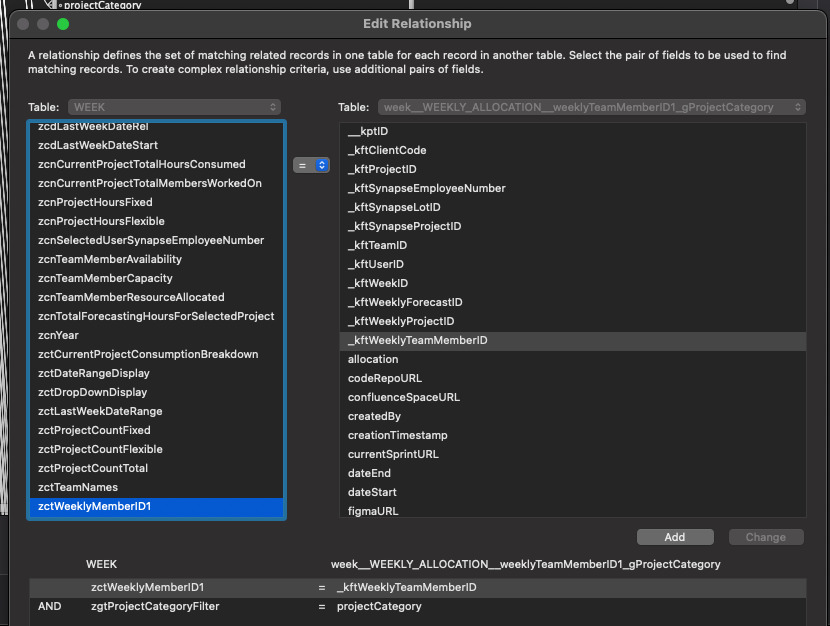
Une relation utilisée pour un portail filtrable
Dans le modèle, l’utilisateur peut définir la valeur de zgtProjectCategoryFilter sur l’une des trois valeurs à l’aide de ces boutons :
Chaque fois qu’un utilisateur modifie la valeur, FileMaker doit vider les données de jointure mises en cache, rétablir le lien et interroger à nouveau les données de jointure pour que la table externe affichée sur le modèle puisse obtenir l’effet de » filtrage « .
Implication sur les performances
Maintenant que nous comprenons les relations et les données de jointure, quelles sont les implications de la nouvelle option de vidage ?
Imaginez que vous ayez un script qui tourne en boucle. Chaque fois qu’il boucle, il met à jour un champ sur le côté gauche d’une relation. Imaginez que cette rubrique soit utilisée dans plusieurs liens et qu’une grande quantité de données de jointure soit récupérée par l’intermédiaire de ces liens. Par défaut, FileMaker effectue une purge et une nouvelle requête chaque fois que la rubrique de gauche est mise à jour. Cela peut avoir de sérieuses répercussions sur les performances de votre solution, en particulier si elle est exécutée sur un réseau étendu/WAN (regardez cette vidéo pour comprendre pourquoi).
Avant la version 20.3.1, nous disposions d’un certain contrôle, mais limité, sur le moment où FileMaker mettait à jour les données de jointure (avec l’action de script Actualiser la fenêtre), mais pas lorsqu’il s’agit d’une boucle qui définit les rubriques utilisées dans les liens. Dans le cas d’un scénario en boucle, FileMaker procède toujours à une actualisation et à une nouvelle interrogation, quelle que soit la nécessité.
Avec la version 20.3.1, cette nouvelle fonctionnalité permet aux développeurs de contrôler le moment où FileMaker doit rétablir le lien et actualiser les données de jointure. Elle nous permet d’éviter les opérations de purge coûteuses lorsqu’elles ne sont pas nécessaires.
Jetons un second coup d’œil aux notes de mise à jour ; cette fois, vous devriez disposer d’un peu plus de contexte :
L’option Purge comprend les trois valeurs suivantes :
1. Systématique : lors de la définition d’une rubrique dans une boucle, le lien est purgé avec les données de jointure.
2. Minimale : lors de la définition d’une rubrique dans une boucle, les données minimales sont purgées.
3. Différée : lors de la définition d’une rubrique dans une boucle, les données et les données de lien ne sont purgées qu’après avoir quitté la boucle.
L’option Systématique est celle que nous avions avant cette version et c’est l’option par défaut. Si vous ouvrez une solution FileMaker utilisant la version 20.3.1+ de FileMaker Pro pour la première fois, toutes les options de vidange de la boucle seront définies sur Systématique. Cette option n’est pas utilisée lorsque c’est nécessaire, mais lorsqu’elle peut l’être.
Différée est rapide. Son comportement est simple : il essaiera de ne rien purger avant de sortir de la boucle. Il n’y aura qu’une seule purge, au total, à la fin.
Minimum est un peu mystérieux. Au moment de la publication de cet article, il n’y a pas de documentation officielle sur cette fonctionnalité autre que ce qui est cité ci-dessus. Le nom semble indiquer que cette option fait quelque chose d’intelligent pour minimiser la quantité de données de jointure purgées pendant la boucle. Sur la base de mes tests, je pense que son comportement se situe entre Systématique et Différée; Minimale essaie d’effectuer le moins de purge possible, à moins que d’autres actions de script dans la boucle ne requièrent une actualisation des liens.
Tests de comportement et de performance
Méthode de test
Pour tester cette fonctionnalité, j’ai utilisé un scénario similaire à celui que j’ai décrit ci-dessus : un champ qui fait partie de neuf relations différentes est mis à jour de manière répétée.
Dans l’exemple précédent, je n’ai montré qu’une seule relation avec le champ global. En réalité, j’en ai neuf.

Neuf relations qui utilisent le champ zgtProjectCategoryFIlter sur le côté gauche
Ce n’est probablement pas la façon la plus intelligente de construire une vue en grille dans FileMaker, mais elle est parfaite pour tester cette nouvelle fonctionnalité.
Le script de test que j’ai utilisé est illustré dans la capture d’écran ci-dessous. Il s’exécute à partir d’un modèle qui utilise ces liens pour afficher des données liées dans des tables externes. Le script effectue de nombreuses boucles et définit à chaque fois la rubrique zgtProjectCategoryFilter avec une valeur différente ; à la fin, il affiche le temps total nécessaire et la liste des données connexes récupérées.
Processus de test et données
Cas de test 1 – 999 boucles, récupération des données de jointure au milieu de la boucle et évaluation des portails
Pour le premier test, à l’intérieur de chaque boucle, j’ai essayé de récupérer une donnée de jointure et de l’enregistrer.
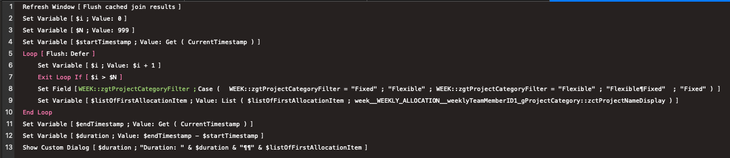
Script utilisé
| Scénario de test | Systématique | Minimale | Différée | |
| 1 | 999 boucles 9 relations 23 enregistrements liés au maximum 2023-11-26 | 22 secondes Les données récupérées en milieu de boucle sont exactes | 18 secondes Les données récupérées en milieu de boucle sont exactes | 1 seconde Les données récupérées en milieu de boucle ne sont PAS exactes. |
| 2 | 999 boucles 9 relations 13 enregistrements liés au maximum 2023-12-10 | 21 secondes Les données récupérées en milieu de boucle sont exactes | 18 secondes Les données récupérées en milieu de boucle sont exactes | ~0 seconde Les données récupérées en milieu de boucle ne sont PAS exactes. |
| 3 | 999 boucles 5 relations 13 enregistrements liés 2023-12-24 | 21 secondes Les données récupérées en milieu de boucle sont exactes | 18 secondes Les données récupérées en milieu de boucle sont exactes | ~0 seconde Les données récupérées en milieu de boucle ne sont PAS exactes. |
Test 2 – 999 boucles, évaluation des portails uniquement
Maintenant, je vais désactiver l’étape qui récupère les données connexes au milieu de la boucle, en ne laissant que la mise en page qui utilise les données de jointure.
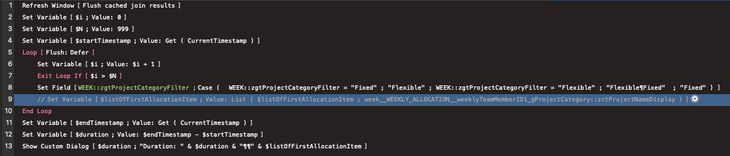
Script utilisé
| Scénario de test | Systématique | Minimale | Différée | |
| 1 | 999 boucles 9 relations 23 enregistrements liés au maximum | 1 seconde | ~0 seconde | ~0 seconde |
| 2 | 999 boucles 9 relations 13 enregistrements liés au maximum | ~0 seconde | ~0 seconde | ~0 seconde |
| 3 | 999 boucles 5 relations 13 enregistrements liés | ~0 seconde | ~0 seconde | ~0 seconde |
Cas de test 3 – 99 900 boucles, évaluation des portails uniquement
Pour tester la surcharge introduite par les mises en page pendant les boucles, j’ai multiplié par cent le nombre total de boucles pour atteindre 99900.
| Scénario de test | Systématique | Minimale | Différée | |
| 1 | 99900 boucles 9 relations 23 enregistrements liés au maximum | 50 secondes | 10 secondes | 8 secondes |
| 2 | 99900 boucles 9 relations 13 enregistrements liés au maximum | 49 secondes | 9 secondes | 9 secondes |
| 3 | 99900 boucles 5 relations 13 enregistrements liés | 47 secondes | 9 secondes | 9 secondes |
Test bonus – 99 900 boucles, évaluation des portails uniquement et visualisation des données laissée accidentellement ouverte avec l’option « évaluation automatique » activée
Le fait d’avoir accidentellement laissé la visionneuse de données ouverte a considérablement ralenti le processus. Même si je ne l’utilise pas pour regarder des données de jointure pertinentes pour mon test.
Conclusions et considérations d’utilisation
- L’option Différée n’efface pas du tout les données de jointure au milieu de la boucle. C’est pourquoi, dans le cas de test 1, les données de jointure au milieu de la boucle récupérées avec l’option Différée sont inexactes.
- Cela confirme le comportement mentionné dans les notes de version.
- Cela explique également pourquoi cette option est la plus rapide des trois.
- Nous ne devrions utiliser l’option Différée que lorsque les données de jointure ne sont pas pertinentes pour la logique de la boucle. Sinon, nous obtiendrons des données erronées.
- L’option Systématique est la plus lente, comme nous nous y attendions.
- Les performances de l’option Minimale se situent entre Systématique et Différée.
- Elle tente de maintenir la précision de l’évaluation des données de jointure au milieu de la boucle, comme le montre le cas de test 1.
- Cependant, plus il y a de « données de jointure évitables », plus cette option devient performante, au point d’être comparable aux performances de l’option Différée (comparez les résultats des cas de test 1 et 3).
- Cela semble être l’option la plus évidente, mais ne me citez pas sur ce point. Attendons la documentation officielle qui clarifie le comportement avant de l’adopter en masse.
- Les différentes opérations qui s’appuient sur les relations ont des surcoûts de performance différents.
- La récupération explicite des données de jointure dans le script introduit un surcoût de performance beaucoup plus important que l’affichage des champs liés dans les modèles (comparez les résultats des cas de test 1 et 2).
- Le nombre de relations touchant le champ de mis à jour n’a pas beaucoup d’importance. Le nombre d’enregistrements liés a un peu d’importance. Cela est logique car le nombre d’enregistrements liés détermine le nombre de données de jointure pouvant être extraites (cas test 3).
- Le visualiseur de données modifie le comportement de FileMaker en matière d’évaluation et de purge (scénario de test bonus).
Une dernière chose
Inspiré par ce fil de discussion, nous pourrions utiliser cette nouvelle option de purge avec la technique de boucle à passage unique pour contrôler le comportement de la purge des données de jointure de l’ensemble du script.
J’espère que cet article vous éclairera sur cette nouvelle fonctionnalité.