Nous sommes des « Problem Solvers » et nous utilisons notre outil Low-Code préféré (FileMaker) pour construire des solutions sur-mesure pour nos clients. La finalité la plus évidente est d’optimiser et de faciliter les processus de l’entreprise en automatisant des tâches qui vont, elles-mêmes, produire des données. Or, ces données brutes reflètent, par définition, l’activité de l’entreprise. Leur analyse permettra aux dirigeants d’avoir une vue fidèle de celles-ci et aidera à prendre les meilleures décisions.
Problème : les données en elle-même sont illisibles en l’état et nécessitent d’être retravaillées, regroupées, sélectionnées, pour en tirer l’information pertinente souhaitée. C’est ici qu’intervient la partie « statistiques » ou « tableau de bord » que va nous demander notre client.
Or, pour traiter des informations, il faut par définition qu’elles existent (nous n’hésiterons pas à ouvrir autant de portes ouvertes que nécessaire dans cet article !), et l’élaboration de tableau de bord peut représenter un certain temps, voire un temps certain. Voici pourquoi réaliser un tableau de bord peut s’avérer le parent pauvre de nos projets par manque du budget nécessaire.
En établissant la liste des méthodes à notre disposition nous verrons que l’une d’elles possède quelques avantages non négligeables, et dont les inconvénients pourraient, en outre, peut-être être surmontés.
Imaginons que nous avons une solution produisant des factures dans une table éponyme :
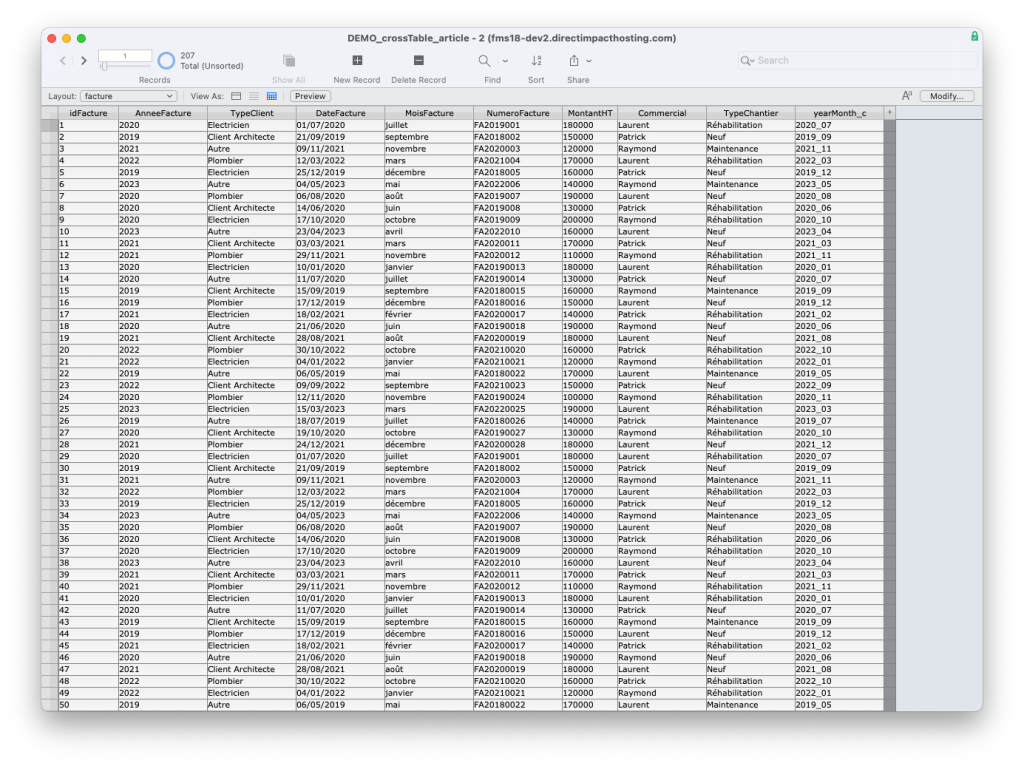
Et que sur la base de de ces factures, notre client nous fasse la demande, sommes-toutes légitime, de savoir combien il a facturé par année depuis l’installation de son logiciel en 2019.
1. Discours sur les méthodes
Sans prétendre à l’exhaustivité, nous pourrions classer les méthodes utilisables en 4 familles : les exports excel, l’utilisation des sous récapitulatifs dans des rapports, les méthodes plus complexes et la confection d’un tableau HTML.
A. L’export Excel
Méthode prisée des amoureux d’Excel qui vont illico comprendre qu’un export est possible sur la plateforme qu’ils maîtrisent, l’export est, reconnaissons-le, une méthode assez rapide et peu coûteuse pour, en quelques minutes, arriver à un tableau croisé dynamique répondant à notre mission.
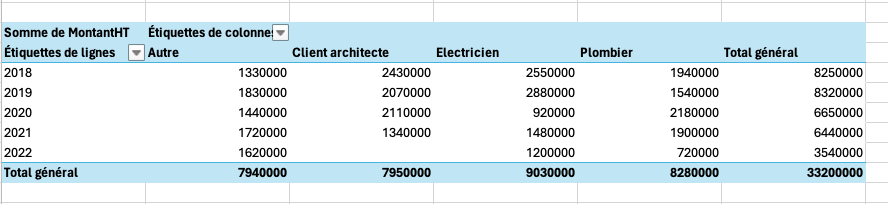
Son inconvénient principal n’est pas neutre: nous voilà sortis de FileMaker, travaillons localement sur notre tableau non partagé et surtout, la moindre modification des données amène à refaire systématiquement les mêmes opérations. Le taylorisme étant d’un autre temps, nous rappellerons à notre client que son temps est précieux et envisagerons d’autres méthodes.
B. Les « sous récapitulatifs après tri sur »
Cet objet de modèle, au nom improbable, peut s’avérer très puissant tant il est performant. Il peut s’obtenir grâce à un assistant ou en l’insérant manuellement dans une liste ; FileMaker est une plateforme qui permet d’avoir facilement beaucoup de rapports, ce qui probablement justifie que j’y ai consacré ma carrière, mais aussi nous permet d’envisager de créer notre tableau croisé dynamique dans un nouveau modèle.

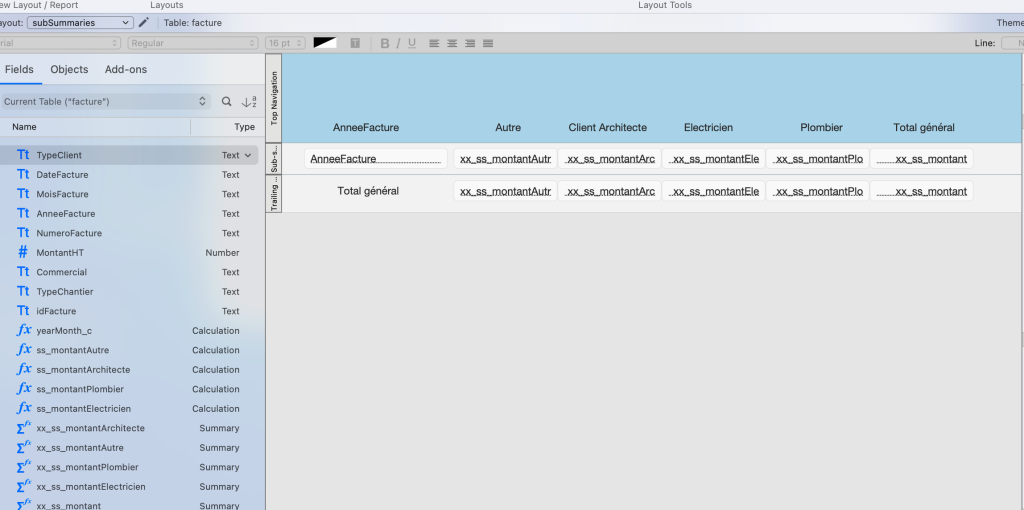
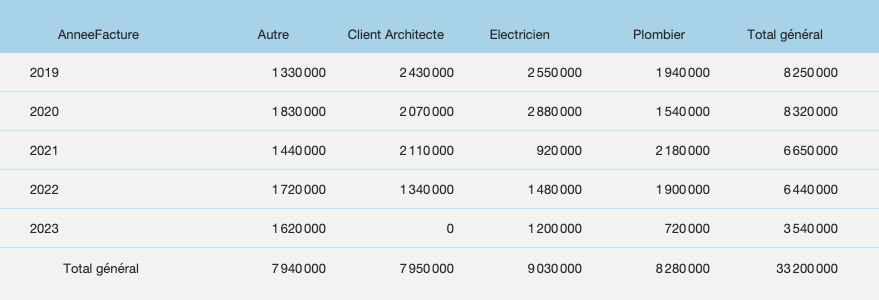
En créant quelques rubriques complémentaires (dans notre exemple, pas moins de 9 quand même) nous pouvons prétendre à obtenir le même tableau, qui s’actualise en un clic, sans sortir de FileMaker. Le progrès est en marche. Peut-on faire mieux ?
C. Les solutions plus « complexes »
D’autres techniques pourraient être évoquées, permettant elles-mêmes d’agréger de l’information.
Nous pourrions utiliser une table « pivot » pour calculer, dans notre exemple, que les 5 années nécessaires. Il s’agirait de remplacer les rubriques de type statistique par des calculs utilisant la fonction « somme »; l’avantage étant d’externaliser les calculs de la table d’origine, et si nécessaire, de regrouper les données de plusieurs tables dans une seule. Les inconvénients majeurs seront la perte de performance et… l’ajout d’une table en plus des rubriques nécessaires.
Nous pourrions imaginer également une « virtual list » qui reprendrait dans un tableau une liste que nous créerions de toutes pièces probablement par script ou un calcul SQL. Cette méthode est finalement assez proche de la technique qui suit, la légèreté en moins puisqu’il faut, là aussi, créer une table pour afficher notre “virtual list”.
D. Le tableau HTML
Tant qu’à construire un fichier texte qui agrège nos données, pourquoi ne pas imaginer un script qui :
- Boucle parmi les factures pour collecter nos données en les rangeant dans un format plus pratique et plus universel qu’une simple liste, j’ai nommé un objet JSON
- Boucle ensuite dans ce même objet pour construire un code HTML avec un tableau affichant le résultat souhaité.
- Afficher ledit code dans un webViewer dont c’est la fonction première.
À l’usage, cette solution s’avère plus complexe, je le concède, avec toutefois ici un avantage qui apparaît de taille : la portabilité. Plus besoin de créer des objets de modèles (à part un simple webViewer), des rubriques, ni des tables, tout est créé par script.
Ce fut en quelque sorte la version 1 de cette méthode, qui m’amena à constater que bien que tout le reste fût simplifié, le script en question pouvait aisément arriver à 200 lignes. Schématiquement, 100 lignes pour agréger les données dans une variable et 100 lignes pour transformer cette variable en un tableau HTML. Et si la statistique en question devait être un peu modifiée, il s’agissait de modifier beaucoup de lignes aux bons endroits. Comme les sages l’avaient annoncé, la liberté avait-elle un prix ?
2. La méthode améliorée
Comment améliorer notre méthode pour n’en garder que les qualités ?
A. Regrouper les données
Premièrement, notons que la fonction de calcul « éxécuter SQL » permet, non seulement, de s’affranchir du contexte, mais outre cela, enrichi d’une instruction « GROUP BY », les données seront automatiquement agrégées selon nos souhaits. Pour notre exemple avec ce calcul :
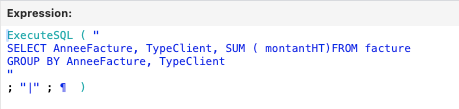
Va nous amener cette liste :
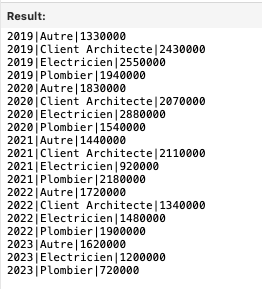
B. Ranger les données
Nous pouvons ranger nos données pour en faire un bel et solide objet JSON. Les plus attentifs, ou du moins, ceux qui sont arrivés à ce stade de ce brillant exposé, questionneront : « pourquoi passer par un objet JSON ?»
Les chemins menants tous à Rome, cette étape n’est en effet pas forcément nécessaire, pour autant cela permet de standardiser nos données, de gérer plus facilement les valeurs nulles (avez-vous noté qu’il n’y a pas de factures d’Architectes en 2023 ?), d’adjoindre des totaux…etc.
Pour nous économiser les boucles par script, pourquoi ne pas imaginer une fonction de calcul pour boucler dans la liste et construire cet objet ?
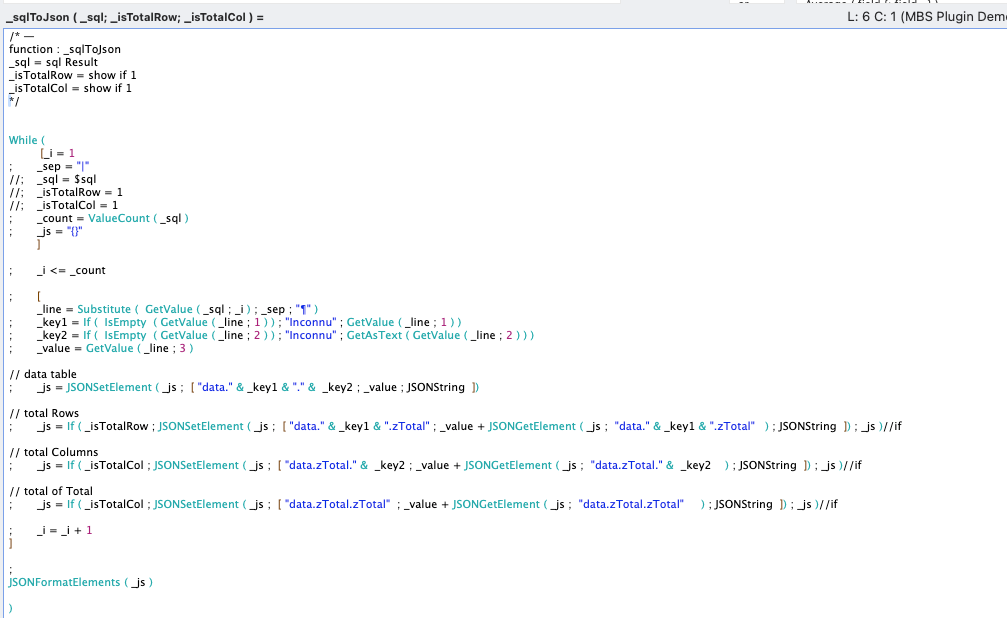
Le résultat de notre requête prendra ainsi cette forme :

C. Afficher les données
Après avoir rangé nos données dans le format le plus standard du moment, notre souhait est désormais de créer, à la volée, un tableau HTML qui affichera ces données. Notre fonction personnalisée _sqlToHTML en charge de transformer le résultat d’une requête SQL en tableau HTML va :
- faire appel à plusieurs fonctions secondaires
- faire une boucle dans le résultat JSON pour créer les lignes du tableau et une autre boucle à l’intérieur de chaque ligne pour créer chaque cellule. Les boucles “While” peuvent être imbriquées, à notre plus grand bonheur!
Le fonctionnement général pourrait être schématisé comme suit :
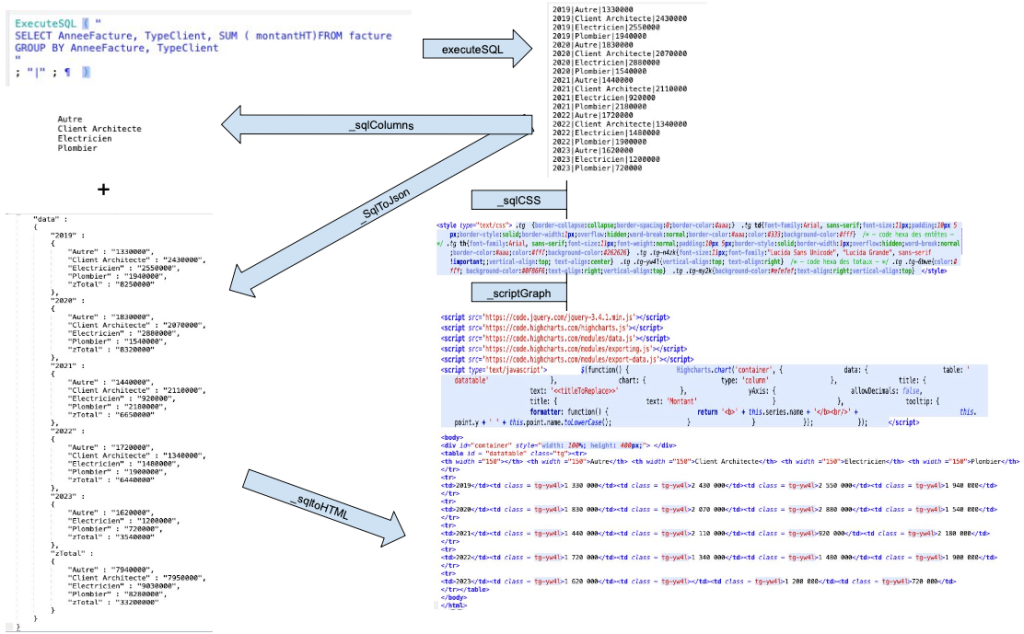
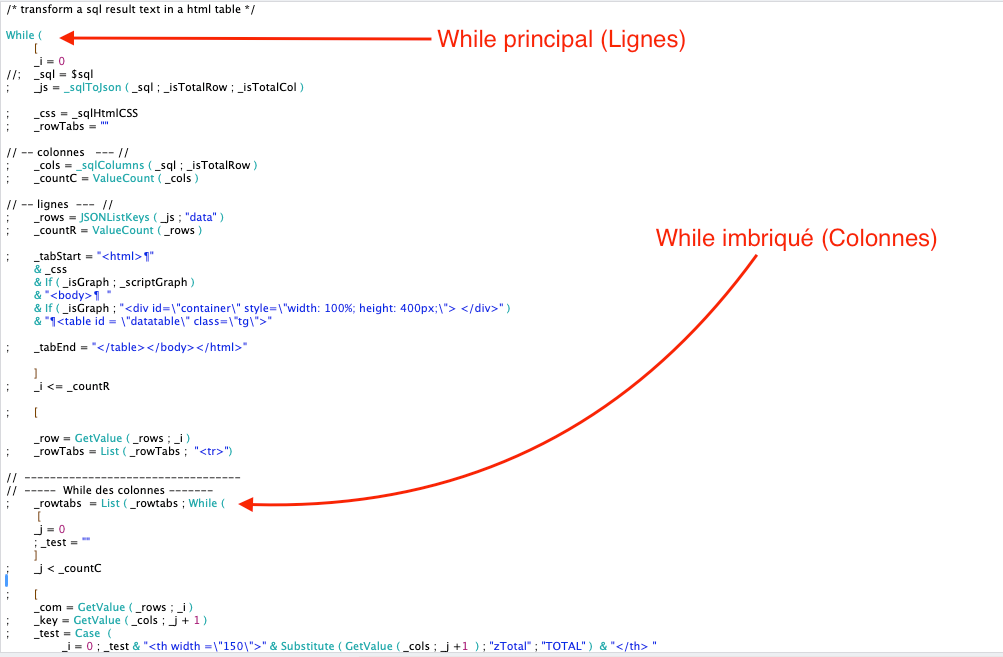
A noter l’utilisation des autres fonctions personnalisées :
- “sqlHtmlCSS” qui, simplement, externalise notre code CSS
- “sqlColumns” qui va parcourir le JSON des résultats pour lister, de façon exhaustive, les colonnes nécessaires.
- “scriptGraph” que nous aborderons plus loin
Au total, en insérant simplement notre requête SQL directement dans notre WebViewer et en lui appliquant notre fonction personnalisée :
Nous obtenons à l’affichage du webViewer ceci :
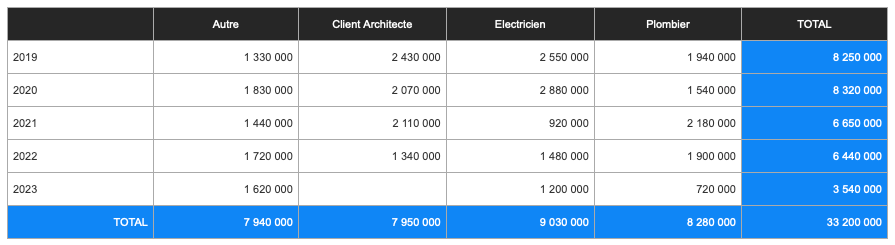
Tout ceci est donc possible avec un jeu de quelques fonctions personnalisées. La portabilité est maximale puisqu’il suffit de copier un jeu de fonctions personnalisées et d’en appeler une seule (qui contient toutes les autres) dans notre WebViewer.
3. La méthode ultime
A. Des améliorations encore possibles?
Ne ne souffrons pas d’excès de perfectionnisme, mais regardons les quelques limites restantes. Nous avons en effet maintenant un tableau de statistiques généré automatiquement en inscrivant une requête SQL dans un WebViewer. Et donc l’envie de multiplier les différents tableaux (pourquoi pas le chiffre d’affaires par typeChantier, ou le chiffre d’affaires mensuel de commerciaux par mois en 2023 ?)
Utiliser cette méthode nous obligerait à multiplier les WebViewers et donc les modèles d’affichage.
En intégrant directement la requête SQL dans le WebViewer il est, en outre, nécessaire de bien connaitre le SQL ainsi que le nom des tables et rubriques.
Certes nous vantions la portabilité maximale qui évitait d’avoir à créer des tables ou des rubriques, pour autant si l’on sacrifie à ce dogme on pourrait imaginer créer une table et des rubriques permettant :
- de créer et sauvegarder autant de tableaux que souhaité (un par enregistrement)
- de construire simplement une requête SQL, ouvrant la possibilité à notre client de faire lui même ses propres statistiques.
Avouons que les avantages en valent probablement la peine…
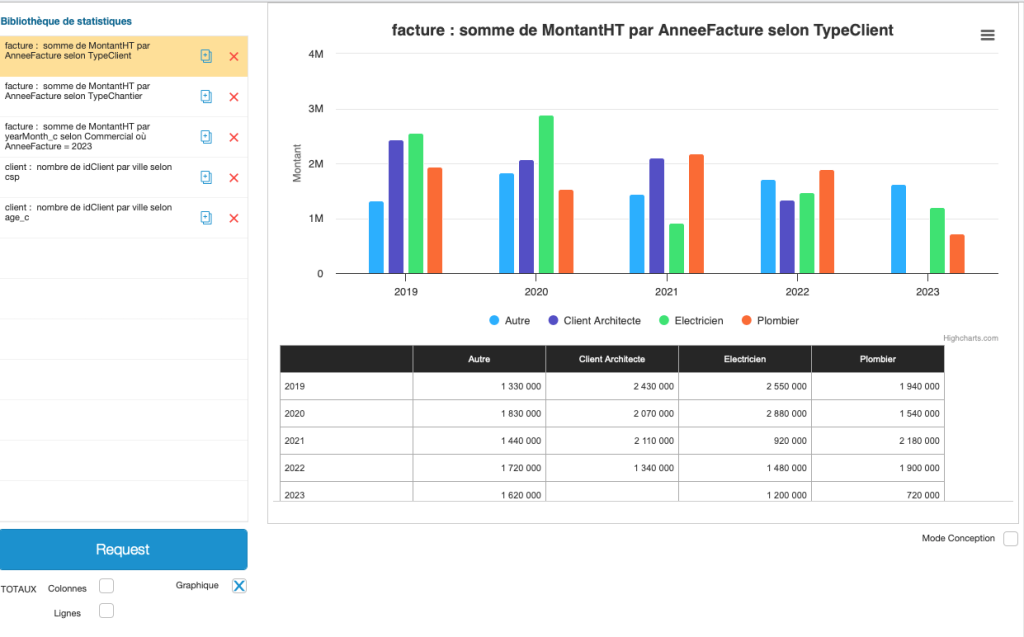
B. Quid des graphiques?
La génération d’un graphique, étant la représentation visuelle de notre requête dans FileMaker, nécessiterait probablement de créer des rubriques, pour y déposer sous forme de listes, les résultats de nos différents calculs sous une forme attendue, des fonctions personnalisées supplémentaires, des scripts, des rubriques… Adieu la simplicité!
Bien nous en a pris, nous avons choisi d’afficher notre résultat sous un format bien plus universel, en l’occurrence du HTML : en adjoignant à notre code des bibliothèques Javascript adaptées nous pourrions imaginer obtenir les graphiques souhaités et, sans faire offense à Claris, probablement plus jolis et interactifs.
Ici nous avons choisi d’intégrer un outil extrêmement puissant qui part directement du tableau que nous avons généré : HighCharts. C’est un outil payant qui justifie son prix par sa facilité d’implémentation, vous trouverez la tarification ici : Buy Highcharts License | Highcharts Online Shop
Dans notre exemple il suffit simplement de nommer notre tableau et Highcharts fait le reste!
A noter que des bibliothèques gratuites existent et pourraient probablement être utilisées, partant du JSON avec les données et non du tableau directement, nécessitant dans ce cas une nouvelle fonction pour convertir notre requête et obtenir le format désiré.
C. Pourquoi une seule table pour nos statistiques?
Notre méthode fonctionnant sur la base d’une calcul ExécuterSql (), elle est indépendante du sacro-saint contexte propre à FileMaker, nous pourrions donc envisager, d’obtenir les données résumées d’une autre table, par exemple, la catégorie socio-professionnelle de nos clients selon leur ville, ou encore leur tranche d’âge.
Voici quelques exemples graphiques tirés des exemples cités ci-dessus :
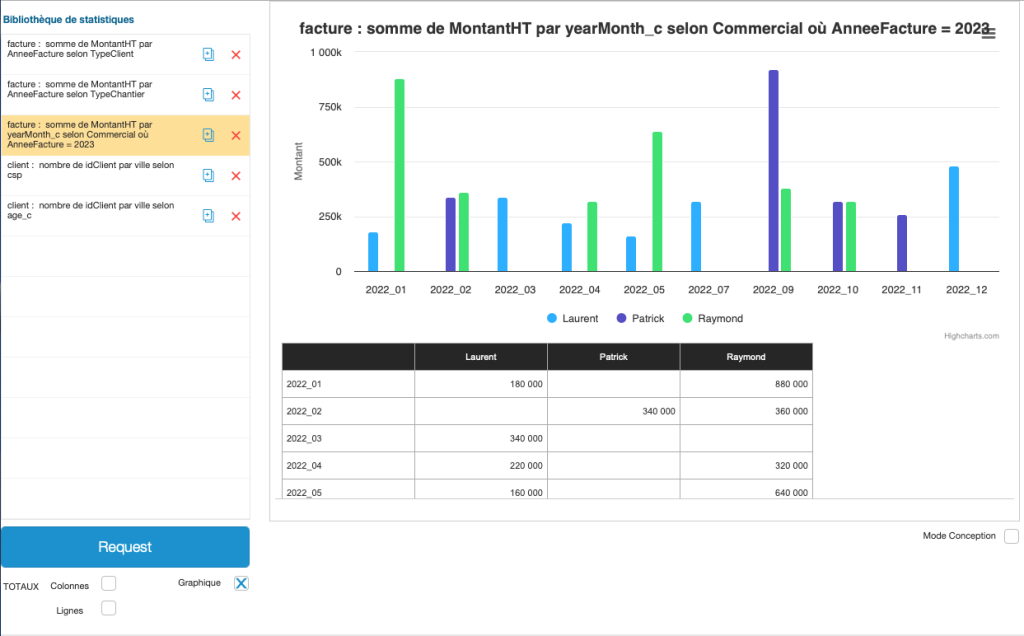
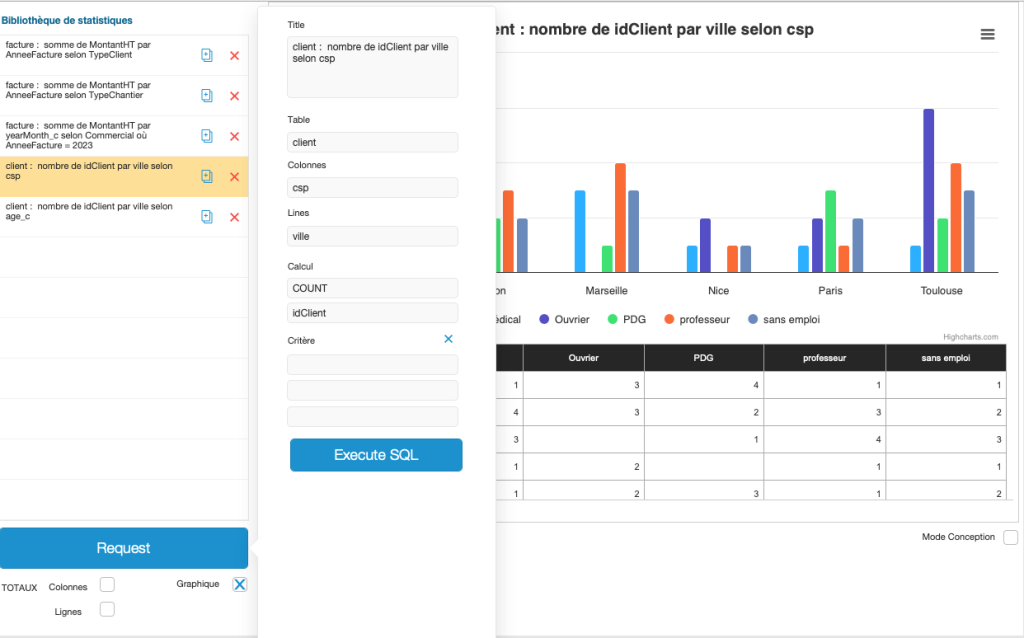
Enfin cette vidéo de 12 minutes vous montrera la facilité d’implémentation de cette méthode sur une solution existante :
Conclusion
La génération de tableaux et de graphiques sur une même page, pour que notre client dispose des éléments décisionnels les plus pertinents, est certainement une partie de la solution avec une grande valeur ajoutée. Cette partie pouvait nécessiter des heures, voire des jours de développement supplémentaires pour être menée à bien, et chaque nouveau besoin du client amenait son surplus de développement.
La combinaison de fonctions de calculs, pour certaines, plus si récentes, nous permet de proposer une façon de faire très facile à installer sur n’importe quelle solution FileMaker.
La méthode présentée ne prétend pas solutionner tous les cas de figure, mais probablement que plus de 80% des cas de figure, ou plus, peuvent être réalisé en quelques minutes. En laissant la main au client, nous pouvons même lui laisser lui-même créer ses propres statistiques auxquelles, probablement, il n’aurait pas pensé. Nul doute que notre client en sera satisfait, et la satisfaction de nos clients, chez Direct Impact, est au coeur de nos valeurs!